离散数学第十一章群与编码笔记
11.1 二进制信息编码与错误检测
一个信息的基本单位被称为message,这是一个从有限个字母表中经有限次排序得到的。本节讨论字母表B={0, 1}。
本文适用于bupt的离散数学,或了解学习群与编码相关知识。
在二元的情况下,我们的基本单位又被称作word,是m个0和1的序列。
其中基本的加法运算定义为: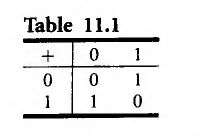 由此我们定义一个群:B^m = B×B……×B(m个),其运算⊕为:(x1,x2,……,xm)⊕(y1,y2,……,ym)=(x1+y1,x2+y2,……,xm+ym)。容易发现这个群的identity=(0,0,……,0)。
由此我们定义一个群:B^m = B×B……×B(m个),其运算⊕为:(x1,x2,……,xm)⊕(y1,y2,……,ym)=(x1+y1,x2+y2,……,xm+ym)。容易发现这个群的identity=(0,0,……,0)。
我们称信息传输过程中的干扰为噪声(noise)。我们期望用编码再解码的形式对数据进行传输,其模型如下: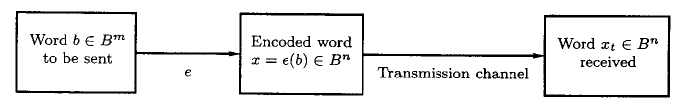
我们说一个code word在传输过程中是with k or fewer errors的,也就是传输结束的word和传输前的word的不同之处小于等于k,但大于等于1。
对一个串x∈B^n,我们定义x的weight=x里1的个数,记号写作|x|(和集合的势写法一致)。
parity (m,m+1) check code:此处定义了一个B^m -> B^m+1的encoding function,即保留其前m位,最后一位由|b|决定。若|b|是偶数则第m+1位=0,为奇数则=1。这和数字电路里的奇偶校验码一致,不过这里是规定放在最末位的。
汉明距离(Hamming distance):其值等于|x⊕y|。事实上不必按这个等式去算,只需要把x和y不一样的位数相加就是结果。汉明距离被用于测量两个串的不同程度。其记号为δ(x,y)。
我们容易发现,汉明距离有以下性质:
(1)交换性,δ(x,y)= δ(y,x);
(2)非负性,δ(x,y)≥ 0;
(3)汉明距离=0等价于两串相等;
(4)三角不等式,δ(x,y)≤ δ(x,z)+ δ(z,y)。从几何直观上这个不等式很容易说明其正确性。
对一个encoding function:B^m -> B^n,定义其minimum distance(最小距离)为对其编码后的所有B^n的串中的最小汉明距离。而且对此有一个定理:它能检测出≤k个错误当且仅当其最小距离大于等于k+1。这一定理告诉我们,当我们能把编码的所有可能性列举出来之后,去算出其最小距离就能知道它的检测错误的数目了。
我们定义group code:对于B^m -> B^n,如果对这个encoding function的值域构成的群是B^n的子群,就称这个函数叫group code。关键在于证明子群这个地方,我们知道,00……0(n个)必须在值域中;且每个值域的元素的逆都是它本身;只需证明其封闭性即可。
对一个群码上的encoding function,它的最小距离=其值域中非0的word的最小weight,即最小的1的个数。有了这一定理,我们不再需要列举汉明距离,只需要寻找最小1的个数即可。
我们定义两个同型矩阵的⊕运算,即对应位置上的+,例如: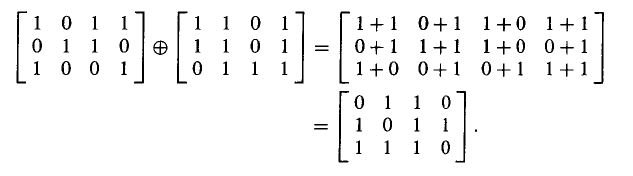
还有两个可乘矩阵的乘法,但此处的乘法不同的是,对应相乘后的相加仍为coding相加,即1+1=0而非传统意义上的布尔加。
容易证得,(D⊕E)*F = (D*F)⊕(E*F),此处均为矩阵,且其形状应满足乘法条件。
下面的定理过于繁琐,略去,取一道例题作为例子研究在给定的矩阵下求encode。 思考顺序为,发现是2->5的encode,然后作差得三,发现H下三行就是三阶单位阵。然后列举定义域中元素,{00,10,01,11},那么在这个变换下前两位保持不动,添加后三位设为x1x2x3,其中x1就等于前两位已知的数和矩阵第一列做矩阵乘法,x2就和第二列做矩阵乘法,以此类推得到结果。
思考顺序为,发现是2->5的encode,然后作差得三,发现H下三行就是三阶单位阵。然后列举定义域中元素,{00,10,01,11},那么在这个变换下前两位保持不动,添加后三位设为x1x2x3,其中x1就等于前两位已知的数和矩阵第一列做矩阵乘法,x2就和第二列做矩阵乘法,以此类推得到结果。
11.2 译码、检错
我们希望对传输的信息经过编码后能正确地译码。本节中的定理同样过于繁琐,此处略去不表,仅阐明做题方法及例题。
我们要记住几个说法:d:B^n -> B^m被称作(n,m) decoding function associated with e,就是我们常见的解码函数,且它是onto的(即所有B^m的串都能被涵盖)。它满足这样一个关系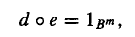
若要证明,只需取B^n中的一个串y,然后写出d(y) = y1y2……ym,然后取B^m中的一个串b,写出(d◦e)(b) = b即可证得上图式子成立。
maximum likelihood decoding function则是更为常用的解码。对这样的maximum function有一个定理:(e,d)函数能correct error的数目k,我们有2k+1 ≤ e,其中e是编码函数的最小距离。这一定理被用于快捷地解决maximum function的纠错数目。
coset leader:即一个群里的coset中weight最小的那个元素。记号写为ε。
我们要对已知的编码进行maximum function解码,关键是列出decoding table。列表方法为:
先把已知的编码好的串横向列出,作为表格的第一行;然后在d函数的值域中任意选取元素,作为下面行的coset leader。注意此处的任意选取,应尽量地从小到大选取,即从00000001开始,然后一直列到这个表格是方的。其中关键的是,表格最左边必然是每一行的coset leader,然后写出最左边的元素之后,用这个串对编码好了的串做⊕运算,结果放在对应的位置。如果coset leader的weight本就是1则不用多考虑,若为2则应查看⊕运算好了的结果是否有weight更小,若是则应更换这个coset leader。最好的办法是,应该先用直观观察运算一次,会不会是coset leader。有的时候写到表格最后几行的coset leader难以寻找,则建议用铅笔按weight给表中元素做标记,寻找可能的还没在表中出现过的元素作为coset leader。值得注意的是,表格是没有重复元素的,故coset leader不应重复。
表格列好了之后,找到待译码的串所在的列,最上面的元素对应的未编码之前的串就是我们要译码得到的结果。
如果parity check是按矩阵形式给出,则需要先用上一节的做法把编码结果写出后再列表。如果我们找到了某个变换对应的coset leader(当然,这通常是不可能直接给出来的),我们分别用这些coset leader对矩阵每一列做矩阵乘法然后堆起来,得到的结果被称为syndrome。有了syndrome则可以对待解码串x直接进行矩阵乘得到x的syndrome,然后查这个syndrome对应的coset leader,用x⊕coset leader后直接译码就是我们的结果。这一方法过于鸡肋,用的不多。
其例子如下图,其中给定矩阵H的形状是6×3。