
离散数学第九章抽象代数笔记
9.1 关系
关系(relation)被用于描述两个集合间的关系。
本文适用于bupt的离散数学,或了解学习群论相关知识。
我们说一个集合A到B的二元关系是一个集合,这个关系集合是A和B集合的笛卡尔乘积构成的大集合的子集。对于a∈A,b∈B,记号写成aRb,或者(a,b)∈R。举个例子,
定义 一个集合A上的关系就是A到A自身的。
我们称一个关系是自反的(reflexive),也就是,在A的任意元素a下,(a,a)∈R。
若一个关系是对称的(symmetric),亦即(a,b)和(b,a)同时∈R。但比较重要的是,我们需要区分asymmetric和antisymmetric。字面意思看来,asymmetric指代完全不对称,从定义上看就是若(a,b)∈R则(b,a)一定不属于R。而antisymmetric是抗对称(字面翻译,我更喜欢这么称呼,事实上这叫反对称),我理解为是不完全的不对称,定义是如果(a,b)和(b,a)∈R,那么a=b。这两个的区分在于a和b是否可以相等。
若一个关系是可传递的(transitive),亦即(a,b)(b,c)∈R时,(a,c)必属于R。我们时刻应该记得,R是一个集合;上述说到的a,b,c都应该在定义的原来集合里面。
关系的复合和集合运算没什么区别,其中留意⊕异或运算符即可。同时记得其表述为composite,复合的意思。做复合判断直接用函数的模型去套用即可,但需要记得顺序,如S◦R应该是先R后S。关系的幂和函数的幂的定义是一样的,即作用几次。
此处有一个定理,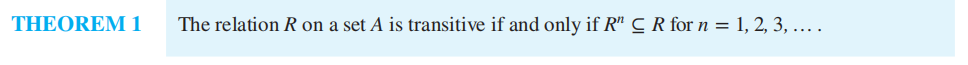 ,即作用无限多次后的关系集合仍为作用一次的子集。
,即作用无限多次后的关系集合仍为作用一次的子集。
9.2 n元关系
n元关系跟9.1提及的关系不同点在于他的维度更多了,表现在R的每个元素都是一个n元组,而非二元组。这里定义这个n叫做degree,度。
数据库模型描述了一个n元关系,如 ,这里的每一条都叫做record(记录),组成了field。我们对数据库模型中能特异性地选出某一个tuple的一个属性叫primary key,也就是所有人的primary key都不同。如图里的id,就是一个primary key。但有的时候我们不想使用这一串primary key,取而代之的用composite key(联合键),如图里的专业和gpa的笛卡尔乘积就是composite key。
,这里的每一条都叫做record(记录),组成了field。我们对数据库模型中能特异性地选出某一个tuple的一个属性叫primary key,也就是所有人的primary key都不同。如图里的id,就是一个primary key。但有的时候我们不想使用这一串primary key,取而代之的用composite key(联合键),如图里的专业和gpa的笛卡尔乘积就是composite key。
n元关系有一个筛选运算,写作Sc(c是下标),即筛选出满足条件C的元素,即n元关系集合里的元素(是一个tuple)。我们可以把他写成像图里的样子。
我们定义n元关系里的projection(投影)运算,即在P下标写上数字,就代表把关系集合里的元素(每一个tuple)内的元素个数都减少了。例如, 。如果projection之后有长得完全一样的tuple则合并起来只写一个。
。如果projection之后有长得完全一样的tuple则合并起来只写一个。
跟projection相对的运算是join。提供两个关系集合,然后把关系集合里每一个元素的维数扩充,然后把多余的信息去掉。
9.3 关系的表示法
我们希望,每次写出一个关系的时候都能更简洁地表示它。这里采用矩阵的形式对其表示法进行化简,写法为 ,即这个矩阵是示性的,是布尔矩阵。例如,
,即这个矩阵是示性的,是布尔矩阵。例如,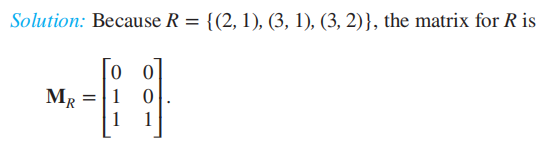
在矩阵表示法里,我们能更清楚看到关系的对称性和自反性,表现为:若一个关系是自反的,矩阵对角线上必全为1;对称的,则矩阵沿对角线对称。
矩阵表示法同样能简化关系的运算。关系的并、交可以化为矩阵对应位置的与和或,例如,
尤其小心的是,对关系的复合,如S◦R,在矩阵运算里必须写法上反过来,因为S◦R实质上是先R后S,也就是写成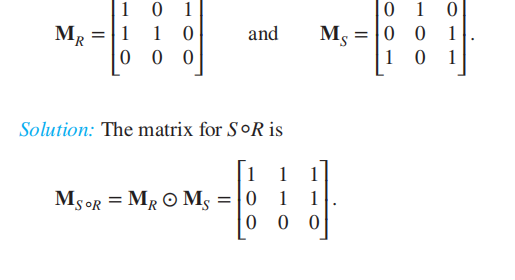 ,这里的运算符号是矩阵积写成布尔矩阵的形式。关系的幂和矩阵幂运算一致。
,这里的运算符号是矩阵积写成布尔矩阵的形式。关系的幂和矩阵幂运算一致。
另一种方法是用有向图表示,用点表示元素,弧表示关系。在图里的自反性体现为同一个点上的弧,像个小圈。对称体现为图的路径是双向的。例子,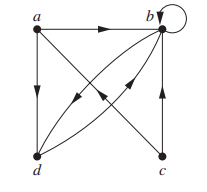
9.4 关系闭包
闭包(closure),即在一些不那么好的关系里,要把它的某个性质补全,补全后的关系称为闭包。例如关系不具有自反性,我们把他补全之后的那个最小的新关系称作自反闭包。
有向图的路径(path):给一个顶点的序列,若能按顺序走遍这个序列(可以重复),则称这个序列为一个路径。若一个路径起点和终点是同一个顶点,这个路径又被称为circuit或circle(环)。这能直观地从画出来的图上比划出来。
从代数层面,关于路径有一个不那么显而易见的结论:如果a到b有一条长度=n的路径,那么这等价于(a,b)属于R^n。可以理解为,作用n次关系后,(a,b)这一映射(我更愿意这么称呼)仍然成立,也就是作用n次,a顶点仍能到达b。
为了推出后面的传递闭包,这里定义:一个连接起来的关系(connectivity relation)称之为R,里面的所有元素(a,b)都是有路径的。因为这些路径是有可能不止一条的,也就是说,路径存在于不同的R^n里(n的值也随之变化),所以可以发现这个定义: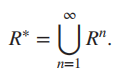
可以发现,这里定义的R,就是我们想要的传递闭包。由此有一个引理,即如果一个有n个元素的关系集合中,(a,b)存在一条长度>=1的路径,那么这条路径长度<=n;更强的一个结论,a≠b的话,路径长度<=n-1。这条引理的证明是反证法,利用鸽笼原理证明最短路径上有环存在,从而推出路径长度<=n。
由此,我们对矩阵表示的关系能更容易找到其传递闭包。由上一张图,我们可以得出: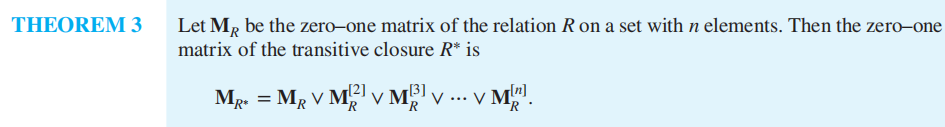
注意到这里的矩阵幂运算常有循环性,我们并不需要去求所有的矩阵,当求出有循环性的矩阵的时候,将已知矩阵取或即可。
除了这一算法,还有Warshall’s Algorithm也能求出所给矩阵的传递闭包。例子:
这个算法的思想就是从当前矩阵出发,逐次按行遍历并连接路径。如这里的W0,第一行表示a能到d,那么我们需要按行遍历整个矩阵,找哪个点能到a,那么它也能到d。然后把找到的点所在那一行到d的位置写为1,遍历一次矩阵得到W1。对W1的第二行遍历,得到W2。以此遍历四次,则得到最后的传递闭包。我们不需要理解为什么这个算法能work,会用即可。
9.5 等价关系
等价关系(equivalence relation)是自反、对称和传递的。如果(a,b)∈等价关系,那么记号可以写作a~b。
等价类的理解对后面商半群理解极其重要,等价类的定义是,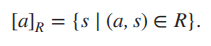 说人话就是,我们有一个等价关系R,我们可以把满足aRs的这一簇元素写成[a],也就是,[a]事实上是一个集合,集合内的所有元素两两都符合aRb,其中a,b∈[a]。其中[a]里任取一个元素,这个元素叫做代表元素(representative)。举个例子,我们对定义在Z上的≡(mod 4)这一运算,我们可以得到0,1,2,3的等价类[0],[1],[2],[3]。其中[0] = {… ,−8,−4, 0, 4, 8, … }。我们发现,等价类这个集合自身也满足等价关系R的三个性质。
说人话就是,我们有一个等价关系R,我们可以把满足aRs的这一簇元素写成[a],也就是,[a]事实上是一个集合,集合内的所有元素两两都符合aRb,其中a,b∈[a]。其中[a]里任取一个元素,这个元素叫做代表元素(representative)。举个例子,我们对定义在Z上的≡(mod 4)这一运算,我们可以得到0,1,2,3的等价类[0],[1],[2],[3]。其中[0] = {… ,−8,−4, 0, 4, 8, … }。我们发现,等价类这个集合自身也满足等价关系R的三个性质。
由等价类的定义,我们可以得出三个等价的命题: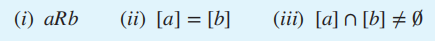
下面我们定义了划分(partition)。我们对一个集合S,可以划分为若干个集合,这些集合都是满足R关系的等价类,这些集合的并集=S,而这些集合交集为空,也就是说,对集合的划分是不重不漏的。
在划分的基础上,我们可以把集合按照等价关系R进行划分。(反过来,我们有一个集合的划分,则必有对应的一个等价关系。)
例如,在全集S = {1, 2, 3, 4, 5, 6}上有划分A1 = {1, 2, 3}, A2 = {4, 5}, A3 = {6}。试求对应的等价关系。
我们知道A1,A2,A3是等价类,即其内部元素两两的笛卡尔乘积属于我们想要的结果等价关系R。由我刚刚提及的,等价类这个集合自身也满足等价关系R的三个性质。我们知道, (1, 1), (1, 2), (1, 3),(2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)∈R,因为A1是个等价类;同理,(4, 4), (4, 5), (5, 4), (5, 5),(6, 6)也属于R。然后就可以写出R了。
9.6 偏序关系
下文写的≤都是偏序的符号,不是原意。要记清楚到底能不能取等。
我们知道,等价关系是自反、对称和传递的。跟等价关系稍有不同的一种是偏序关系(partial ordering/partial order),偏序关系满足自反性、antisymmetric(抗对称性),传递性。一个满足偏序关系R的集合S称为partially ordered set,或poset,记号为(S,R)。如果(a,b)∈R,我们的记号写为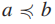 这里下端带上等于,表示a可以等于b;不带上等于号的记号则表示a不能等于b。
这里下端带上等于,表示a可以等于b;不带上等于号的记号则表示a不能等于b。
我们说在poset(S,≤)里两个element a和b是可比的(comparable)等价于a≤b或b≤a。若不满足则称不可比的(incomparable)。
当poset(S,≤)里元素两两之间都是可比的,我们称S为totally ordered/linearly ordered set/chain,≤称为total order/linear order。
下面我们定义:如果(S,≤)是totally ordered set,且有一个最小元e(下文有定义),我们称(S,≤)是一个well-ordered set(良序集)。这里不妨用(N,≤)去理解。
当一个≤运算是lexicographic ordering,满足:当a1 ≺ b1或 a1 = b1且a2 ≺ b2,则写作(a1, a2) ≺ (b1, b2)。注意到,在写式子(S,≤)的时候是带等号的,但在应用上不带等号。
介绍hasse diagram:这一图像用于找到偏序集合(S,≤)的covering relation。我们称y cover了x,这等价于x≺y且没有z使得x≺z≺y,直观理解是这条路径是直接的。然后这样的(x,y)组成了covering relation。
hasse diagram的画法应为:按图的方式画出关系,首先去掉自反的小环,然后去掉传递性的环,最后把箭头去掉。但应记得,原本图是有方向的,即如果我们从下往上画,我们原本能到达的路径不能去掉,例如: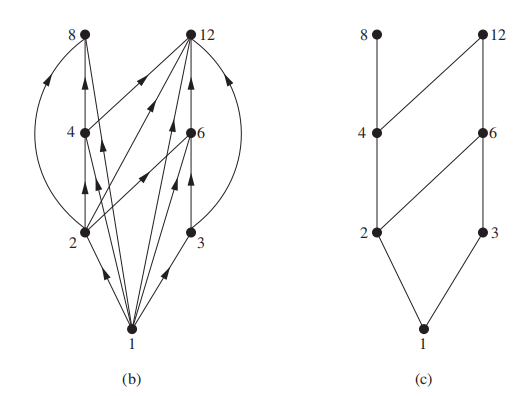 ,我们不能把2->6,4->12抹掉,因为抹掉之后原来能到达的路径现在无法到达(因为没办法往下走)。
,我们不能把2->6,4->12抹掉,因为抹掉之后原来能到达的路径现在无法到达(因为没办法往下走)。
covering relation的意义在于,给定的covering relation的自反且传递闭包就是一个poset。
偏序关系中较难区分的点是最大元(greatest element)、最小元(least element)、极大(maximal)元、极小(minimal)元。极大元a指S里没有一个元素b能满足a≺b;极小元指S里没有一个元素能满足b≺a。从hasse图上看,分别是最高的点和最低的点。而最大元a指对所有元素都满足b≤a,最小元指对所有元素都满足a≤b。我们可以看出,最大元和最小元不一定存在,但极小元和极大元一定存在;最大元和最小元是正向定义的,而极小元和极大元是用否命题定义的,这两者中最大元和最小元是更强的。
此外还有界(upper bound和lower bound)的定义。对A集合的子集B,这个确界是定义在子集B上的,我们从A中取一个元素a,如果满足任意b∈B都有b≤a,则称这个a为B的上界(upper bound)。同理可以定义lower bound。而且,这个上界/下界有可能也在B集合里。在多个upper bound里,我们称最小(按最小元里那个定义)的那个为least upper bound,同理也有greatest lower bound,分别记为lub(A)和glb(A)。
格(lattice)是定义在偏序集合上的。lattice的定义是,lattice集合里每一对元素都有lub和glb。举个例子,
对格,我们定义两个运算,若a,b是格中元素,a∨b是求这两个元素的lub,反之同理。
拓扑排序(topological sorting)的正确性不再细述。实现拓扑排序,第一步是画出hasee diagram。过程是迭代地找极小元。当极小元有多个时,任选其一即可。最后排序完成得到最终的序列集合。例子如图。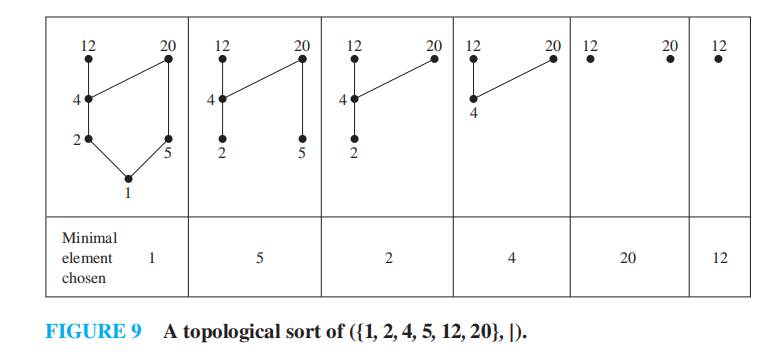
9.1 二元关系
我们知道,在集合A上定义的二元运算是一个定义域为A×A,映射到A的函数。而且二元运算是处处定义的。我们知道二元运算是一个函数,因此二元运算对应的结果唯一。通常的记号为a*b。通常对于a∈A,b∈A,而a*b∈A,我们称对于A上的运算*是闭的(closed)。在检查一个运算是不是二元运算时,通常检查是不是有元素在运算后能算出去集合的范围,如果算出去了则不是二元运算。
当二元运算写成表格的形式的时候,表格的横竖都会是A的各个元素,如图所示。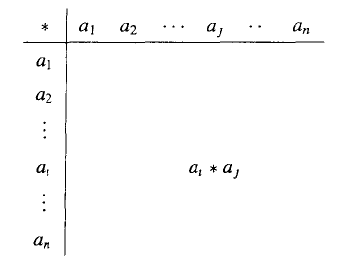 注意按列方向排列的元素是第一个字母a,而按行方向排列的元素是第二个字母b。
注意按列方向排列的元素是第一个字母a,而按行方向排列的元素是第二个字母b。
如果二元运算满足a*b = b*a,则称它是可交换(commutative)的。结合性(associative)也和平时的形式一致,这里不再给出。幂等律定义为a*a = a。
9.2 半群
一个半群(S,*)是指S和其上的associative的二元运算。我们称一个半群是可交换的,也就是其上的二元运算是可交换的。对于一个半群(S,*),我们取S的幂集S*,那么(S*,*)称为由S产生的自由半群(free semigroup generated by S)。
对于半群,如果有一个元素e满足 e*a = a*e = a,我们称这个元素e是半群的幺元(identity)。这样的具有幺元的半群称为幺半群(monoid)。
下面我们引入子半群和子幺半群的概念。对于(S,*)中S的子集T,如果T上的运算是闭的,那么(T,*)称为S的子半群(subsemigroup)。如果(S,*)是个幺半群,且e∈T,那么(T,*)是(S,*)的子幺半群(submonoid)。
同构(isomorphism)是一个函数。对于已知的两个半群(S,*)和(T,*`),我们定义f:S->T,其中f是双射(one-to-one correspondence)而且满足f(a*b) = f(a) *` f(b),那这个函数f即为这两个半群的同构。同样的,f是双射说明f反函数存在,且易证f^-1是(T,*‘)到(S,*)的同构。同构还有另一种说法,即(S,*)和(T,*`) are isomorphic。写作S≃T。
要证明两个函数同构(这里的同构通常是形容词),我们需要找到同构函数f。步骤通常为,定义一个f:S->T,Dom(f)(定义域)=S;然后去证f是one-to-one和onto的,最后说明f(a*b) = f(a) *` f(b)正确。这是很格式化的,要记住。
同态(homomorphism)也是函数。但同态的要求相对较弱,只需要f是处处定义的,不需要是双射。同态函数f也应满足f(a*b) = f(a) *’ f(b)。如果同态函数f是onto的,我们称f:S->T中的T是S的homomorphic image。
对两个满足同态的幺半群,易证f(e) = e`。
同态对S的子半群S’,可以知道S’经过f的变换之后的半群T’,是T的子半群。
同态不改变变换前后运算的commutative。
9.3 乘积半群、商半群
我们定义,对两个半群(S,*)和(T,*`),我们可以得到另一个已知的半群(S×T,*``),其中这里的*``不是新运算,是由原有运算产生的:(s1,t1)*``(s2,t2)=(s1*s2,t1*`t2)。切记。
定义一个半群上等价关系R,如果aRa’和bRb’能推出(a*b)R(a`*b`),那这个关系R叫做同余关系(congruence relation)。
回忆同余类的定义[a],这个[a]是经由同余关系R切分而来的,这些同余类作为元素又组成了一个大集合,称作S/R。这个S/R是集合的集合。我们强行定义了一个运算⊛,使得⊛:S/R×S/R->S/R,且[a]⊛[b] = [a*b],其中*来自(S,*)。那么满足这些性质(S/R,⊛)是一个半群,称为S的商半群。
可以证明,幺半群的商半群也是个幺半群。
我们同样能找到一个函数f:S->S/R,其中fr(a)=[a],说人话就是,fr就是那个分类函数,把a分类到[a],且fr是一个满射的同态,叫做自然同态(natural homomorphism)。
基本同态定理我们定义(S,*)到(T,*`)的满射的同态,如果S里的aRb等价于f(a) = f(b),那么:R是个同余关系;(T,*`)和(S/R,⊛)是同构的。
我们可以构造一个f-bar,让S/T映射到T。有一个图形需要记住: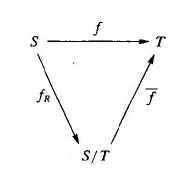
9.4 群
一个群(G,*)拥有以下三点性质:结合性;对于元e,满足任意元素a,a*e = e*a;且对于这个元,a*a` = a`*a = e。这个元同时是可逆元和交换元(我喜欢这么称呼)。这里的a`称为a的inverse(逆)。而且,G的运算closed。
我们称一个群Abelian(阿贝尔群),等价于其所有元素都满足ab=ba。
可以证明,a的逆在G中唯一;且等式满足左消去律和右消去律。对复合求逆,满足穿脱原则。
对群的一个线性方程组ax=b或ya=b(我更喜欢这么称呼),是具有唯一解的。
对一个群G,order of G = G中元素个数。
我们对群的运算,能画出其运算表格。运算表格满足,每一行每一列都不能有重复元素,类似数独。例如对order=4的群,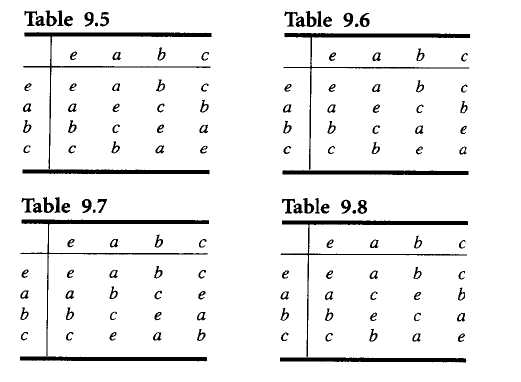 容易发现,这些还是阿贝尔群。
容易发现,这些还是阿贝尔群。
群的一个关键例子,三角形对称群。我们可以定义一个函数,如图所示: 这里的矩阵第二行从左到右分别表示:把1放到当前2的位置上,2放到当前3的位置上,3放到当前1的位置上。不要理解错误!对这样的三角形的这样的旋转变换函数可以找到六个,以矩阵形式,构成S3={f1,f2,f3,g1,g2,g3}。然后定义运算:
这里的矩阵第二行从左到右分别表示:把1放到当前2的位置上,2放到当前3的位置上,3放到当前1的位置上。不要理解错误!对这样的三角形的这样的旋转变换函数可以找到六个,以矩阵形式,构成S3={f1,f2,f3,g1,g2,g3}。然后定义运算: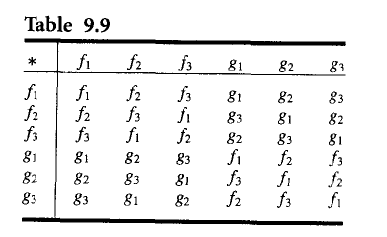 这样我们就得到了这个群。
这样我们就得到了这个群。
这里引入这样的记号Sn,Sn是一个群,其中每一个元素都是像上面的permutation变换矩阵,那么Sn共有n!个元素。
容易发现,这不是阿贝尔群。
半群中有子群的概念,即子群上的运算是闭的,群也有子群的概念。群的子群H满足:单位元e也得在H中;H的任意元素a,那么a的逆也要在H里;H是闭的。
一个群G本身G和{e}是其子群,称为trivial group。
对n个字母的字串全排列,其运算为composition,称为symmetric group on n letters;这个群有一个子群,即其偶排列(even permutation),称为alternation group on n letters。
此外,群的同构、同态和半群上的一致,因为群同时也是半群。
9.5 群的乘积与商
我们定义两个群的乘积仍为一个群,其表示如向量(a1,b1)(a2,b2)=(a1a2,b1b2)。商群同样也定义在同余关系R下,其余的和商半群的定义完全一样。
我们取G的一个子群H和G里的一个元素a,那么H在G里的左陪集(left coset)就是aH={ah|h∈H},右陪集同理。如果aH=Ha对任意a成立,我们说G的子群H是normal(正规的)。
但需注意,Ha=aH并不能推出ha=ah(h是H中的元素)。事实上,ha=ah`,h`是H里的某个元素而已,并不能说他就是h。
我们想要求一个子群H的陪集,事实上并不需要遍历G中所有的元素,因为可以证明,如果a∈H,那么aH=H,这一性质极常用。换句话说,我们只需要遍历H涵盖不到的元素即可。
R是个定义在G上的同余关系,让H是[e],即包含identity的等价类。可以得出,H是个正规子群。这说明,G/R事实上包含了[e]的所有左陪集。
下面引出一个新定理。N是G的一个正规子群,aRb等价于a^-1 * b属于N。然后我们可以推出(1)R是G上的同余关系(2)N是由R切分出来的包含identity的等价类[e]。
由此我们可以看出,由G上的同余关系切分出来的等价类总是G的某个正规子群的陪集;反过来说,G的正规子群的陪集总是由G上的某个同余关系切分出来的。
这里引入一个来自https://heyewuyue1.github.io/2021/10/27/discreteMathMidTerm/ 的算法,来求出所给群的所有正规子群。将单位元e放入结果集合中,再加入任一元素,然后加入该元素的逆元和任意次幂,然后再加入上一步加入的元素的逆元和任意次幂,直到这个群封闭为止。然后判断满不满足Ha=aH这一关系即可。
我们定义核(kernel)的概念。f是群G到群G`的同态函数,定义f的kernel:
ker(f) = {a∈G|f(a) = e`}
我们得到:(1)ker(f)是G的一个正规子群(2)商群G/ker(f)和G`同构。
从而,如果aRb等价于f(a)= f(b),那么ker(f)= [e]。