1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
|
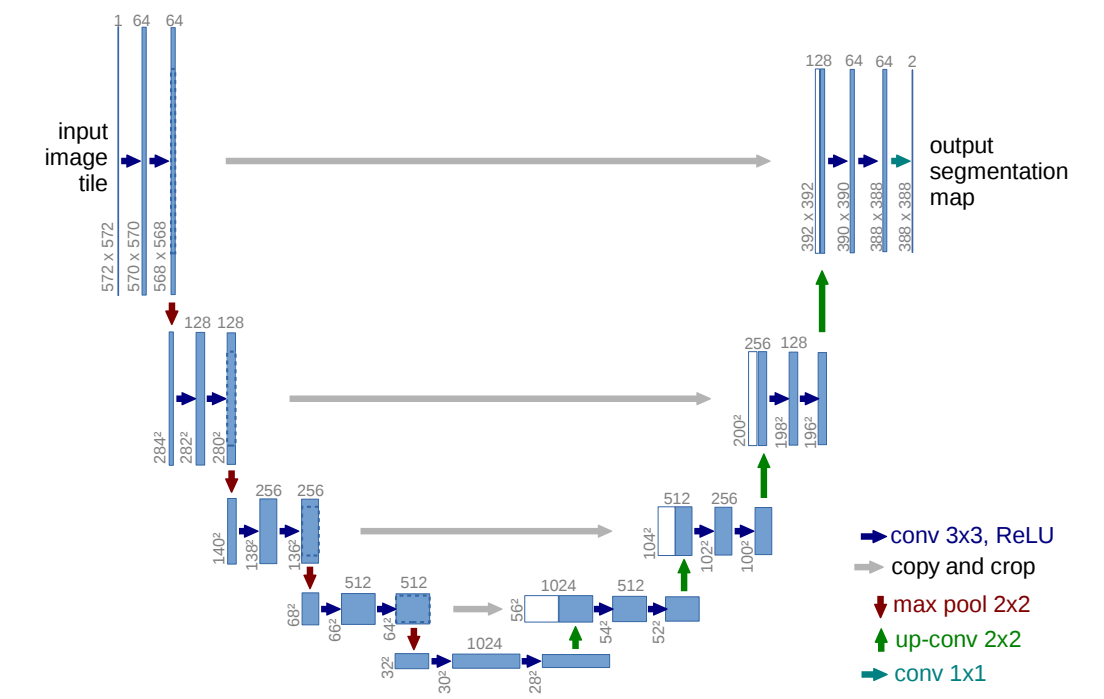
# 网络结构
import torch
from torch import nn
import torch.nn.functional as F
from torchsummary import summary
from torchvision.transforms.functional import crop
def conv_block(in_channel, out_channel):
# return nn.Sequential(
# nn.Conv2d(in_channel, out_channel, kernel_size=3, bias=False),
# nn.BatchNorm2d(out_channel),
# nn.ReLU(),
# nn.Conv2d(out_channel, out_channel, kernel_size=3, bias=False),
# nn.BatchNorm2d(out_channel),
# nn.ReLU()
# )
# 为了妥协一个尺寸 被迫加个padding
return nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU()
)
def up_conv_block(in_channel, out_channel):
return nn.Sequential(
nn.ConvTranspose2d(in_channel, out_channel, kernel_size=2, stride=2),
nn.BatchNorm2d(out_channel),
nn.ReLU()
)
class UNet(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = conv_block(3, 64)
self.conv2 = conv_block(64, 128)
self.conv3 = conv_block(128, 256)
self.conv4 = conv_block(256, 512)
self.conv5 = conv_block(512, 1024)
self.dropout = nn.Dropout()
self.max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.upconv1 = up_conv_block(1024, 512)
self.conv6 = conv_block(1024, 512)
self.upconv2 = up_conv_block(512, 256)
self.conv7 = conv_block(512, 256)
self.upconv3 = up_conv_block(256, 128)
self.conv8 = conv_block(256, 128)
self.upconv4 = up_conv_block(128, 64)
self.conv9 = conv_block(128, 64)
self.conv_predict = nn.Conv2d(64, 1, kernel_size=1)
def forward(self, X):
X1 = self.conv1(X)
X2 = self.conv2(self.max_pool(X1))
X3 = self.conv3(self.max_pool(X2))
X4 = self.conv4(self.max_pool(X3))
X5 = self.upconv1(self.dropout(self.conv5(self.max_pool(X4))))
X4_crop = X4.clone().detach()[:, :,
(X4.shape[2] - X5.shape[2]) // 2: X5.shape[2] + (X4.shape[2] - X5.shape[2]) // 2,
(X4.shape[3] - X5.shape[3]) // 2: X5.shape[3] + (X4.shape[3] - X5.shape[3]) // 2 ]
X6 = self.upconv2(self.conv6(torch.cat([X4_crop, X5], dim=1)))
X3_crop = X3.clone().detach()[:, :,
(X3.shape[2] - X6.shape[2]) // 2: X6.shape[2] + (X3.shape[2] - X6.shape[2]) // 2,
(X3.shape[3] - X6.shape[3]) // 2: X6.shape[3] + (X3.shape[3] - X6.shape[3]) // 2 ]
X7 = self.upconv3(self.conv7(torch.cat([X3_crop, X6], dim=1)))
X2_crop = X2.clone().detach()[:, :,
(X2.shape[2] - X7.shape[2]) // 2: X7.shape[2] + (X2.shape[2] - X7.shape[2]) // 2,
(X2.shape[3] - X7.shape[3]) // 2: X7.shape[3] + (X2.shape[3] - X7.shape[3]) // 2 ]
X8 = self.upconv4(self.conv8(torch.cat([X2_crop, X7], dim=1)))
X1_crop = X1.clone().detach()[:, :,
(X1.shape[2] - X8.shape[2]) // 2: X8.shape[2] + (X1.shape[2] - X8.shape[2]) // 2,
(X1.shape[3] - X8.shape[3]) // 2: X8.shape[3] + (X1.shape[3] - X8.shape[3]) // 2 ]
X9 = self.conv9(torch.cat([X1_crop, X8], dim=1))
return torch.sigmoid(self.conv_predict(X9))
X = torch.randn([1, 3, 304, 304])
net = UNet()
# summary(net, (3, 304, 304))
# data_loader
from torchvision.transforms.transforms import ToTensor
from PIL import Image
import os
from torchvision import transforms as T
import random
import matplotlib.pyplot as plt
class FaceDataSet(torch.utils.data.Dataset):
def __init__(self, path='/content/drive/MyDrive/UNet/Face_Dataset'):
self.path = path
def __getitem__(self, index):
directory_list = os.listdir(self.path + '/Pratheepan_Dataset/FacePhoto')
pic_name = directory_list[index]
image = Image.open(self.path + '/Pratheepan_Dataset/FacePhoto/' + pic_name)
pic_name = pic_name[:pic_name.rfind('.') + 1] + 'png'
GT = Image.open(self.path + '/Ground_Truth/GroundT_FacePhoto/' + pic_name)
transform = T.Compose([
T.ToTensor(),
# T.RandomHorizontalFlip(),
# T.RandomAffine(0, scale=(0.9, 1.1))
])
image = transform(image)
GT = transform(GT)
if random.random() > 0.5:
image = T.functional.hflip(image)
GT = T.functional.hflip(GT)
if random.random() > 0.5:
scale = random.uniform(0.7, 1.3)
transform = T.Compose([T.Resize((int(scale * image.shape[1]), int(scale * image.shape[2])))])
image = transform(image)
GT = transform(GT)
shape = (16 + (image.shape[1] // 16) * 16, 16 + (image.shape[2] // 16) * 16)
transform = T.Compose([T.Resize(shape)])
image = transform(image)
GT = transform(GT)
return image, GT[:1, :, :]
def __len__(self):
return len(os.listdir(self.path + '/Pratheepan_Dataset/FacePhoto'))
data_loader = torch.utils.data.DataLoader(dataset=FaceDataSet(), batch_size=1, shuffle=True)
loss_list = []
# train
def train(dataLoader, trainModel):
net = trainModel
optimizer = torch.optim.Adam(net.parameters(), lr=0.002, betas=(0.5, 0.999))
criterion = nn.BCELoss()
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1, verbose=True) # 打印信息
def init_weights(m): # 初始化参数,极其重要,且极大加快了训练速度
if type(m) == nn.Conv2d:
nn.init.kaiming_uniform_(m.weight) # kaiming初始化 过于厉害
elif type(m) == nn.BatchNorm2d:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0.0)
net.apply(init_weights)
for epoch in range(10): # 跑10个epoch(一个epoch就是对样本集所有样本的遍历)
runningLoss = 0.0 # 初始化loss
for i, data in enumerate(dataLoader, 0): # 枚举loader,写法固定为index,data
inputs, labels = data # data中就是我们刚才定义的__getitem__的顺序
optimizer.zero_grad() # 初始化梯度,必须要有
outputs = net(inputs) # 把data中的样本放入net而不放入标签,得到outputs输出
loss = criterion(outputs, labels) # 根据outputs和原有的标签计算交叉熵
loss.backward() # 反向传播计算更新参数,必须要有
optimizer.step() # 更新参数
runningLoss += float(loss.data) # 把一个epoch中的loss更新
scheduler.step(epoch + i / len(dataLoader)) # 更新lr
print(f'now batch {i}, loss on batch: {loss}')
print(f'epoch{epoch}:', runningLoss)
loss_list.append(runningLoss)
# if len(loss_list) > 0:
# if runningLoss < loss_list[-1]:
# torch.save(net.state_dict(), '/content/drive/MyDrive/UNet/unet.pth')
# else:
# torch.save(net.state_dict(), '/content/drive/MyDrive/UNet/unet.pth')
torch.save(net.state_dict(), '/content/drive/MyDrive/UNet/unet.pth')
plt.plot(loss_list)
plt.show()
print('finish!')
# use
# train(data_loader, net)
net = UNet()
net.load_state_dict(torch.load('/content/drive/MyDrive/UNet/unet.pth'))
# torch.set_printoptions(profile='full')
data = data_loader.dataset[0]
display(T.Compose([T.ToPILImage()])(data[0]))
display(T.Compose([T.ToPILImage()])(data[1]))
output = net(data[0].unsqueeze(0))[0]
zero = torch.zeros_like(output)
one = torch.ones_like(output)
temp = torch.where(output >= 0.5, one, output)
processed_output = torch.where(temp < 0.5, zero, temp)
display(T.Compose([T.ToPILImage()])(processed_output))
|