
CNN基础 & CV基本应用
卷积的概念不多叙述。
其中卷积维度相关的notation见下图:
LeNet
LeNet是用于对28*28的灰度图片分类的网络。其架构简化为下图: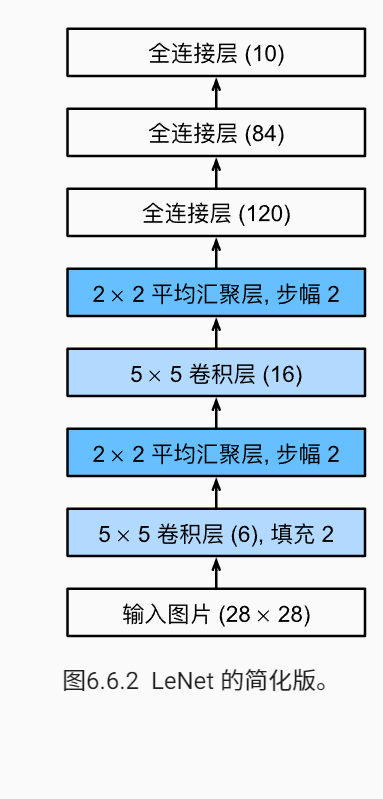
对这一架构复现的代码如下:(隐去了引入数据集这一步)
1 | import torch |
AlexNet进行迁移学习
其架构见下图,其中论文中描绘的不很清楚,也有部分出入。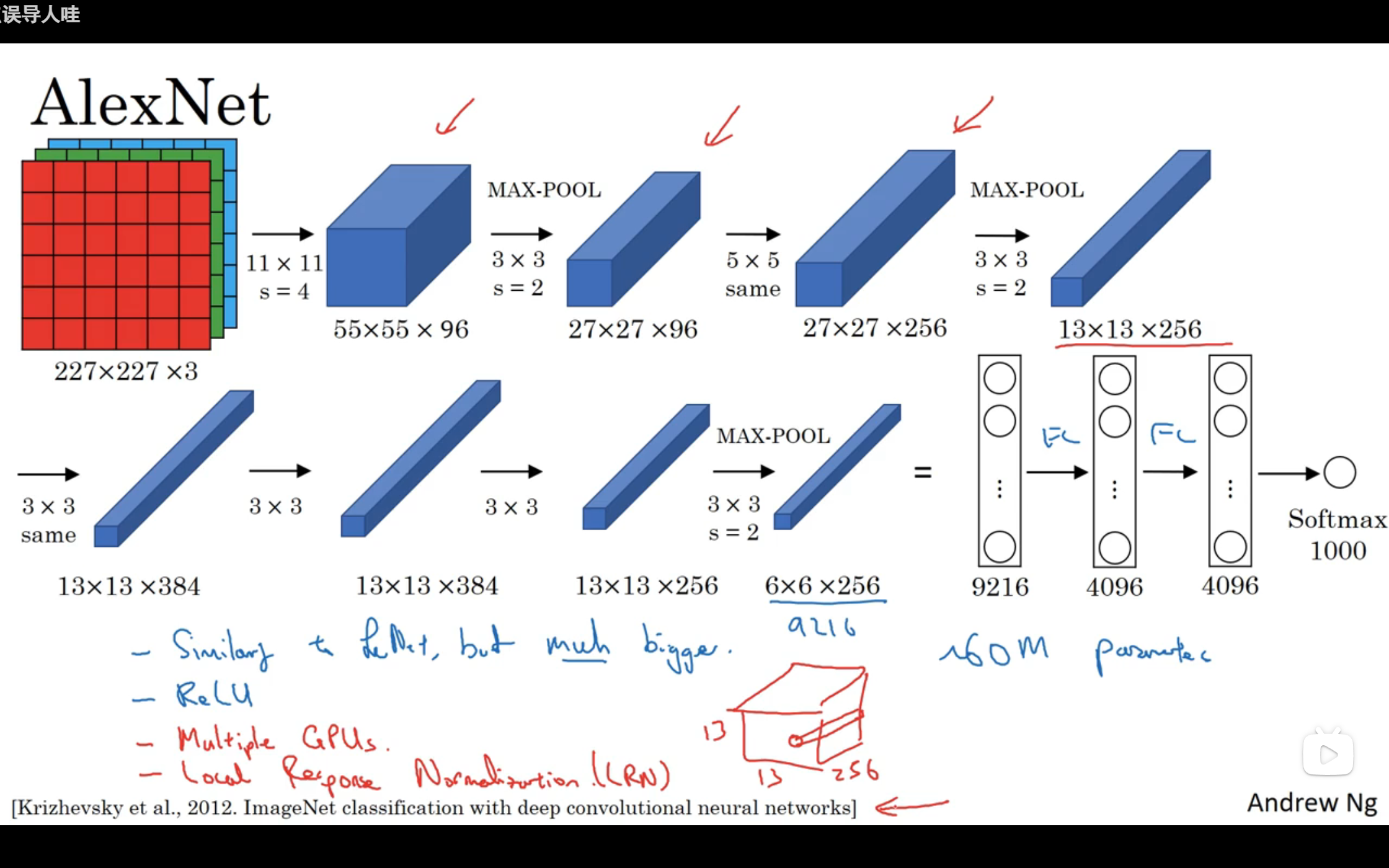
以AlexNet为例,实现迁移学习:
代码块1:导入torch的alexnet:
1 | import torch |
代码块2:载入数据集(狗种类数据集)和数据集处理
1 | from PIL import Image |
代码块3:指定训练过程、冻结参数和新建自己的分类层
1 | model.classifier[6] = nn.Linear(in_features=4096, out_features=120) # 在AlexNet在这个位置修改成我们想要的分类120种狗狗 |
AlexNet复现
直接上代码,kaiming初始化真的猛。与LeNet相比,这里的主要变化是使用更小的学习速率训练,这是因为网络更深更广、图像分辨率更高,训练卷积神经网络就更昂贵。
1 | import torch |
VGG
VGG将conv-activate-poolling的模式封装起来,超参数为convNum。而且VGG论文中提及,深层且窄的卷积(即 3×3 )更有效。
这里的train和dataset代码和上一个相同,只给出网络架构的实现。
1 | def vggBlock(convNum, inChannel, outChannel): # 定义vgg里面的一块 |
NiN
NiN给出的结论是,如果后续用全连接层进行学习,有可能完全放弃表征的空间结构。NiN使用了1*1的卷积,充当逐像素的全连接层,具体类似VGG的块,不过VGG的块是conv-activate-poolling,NiN是Conv-1*1Conv-1*1Conv-Pool(激活在每个Conv后都有,这里不写出)。1*1有时称为bottleneck层,这可以减少计算量。
NiN中最后有一个AdaptiveAvgPool2d,比如说一个5channel的28 * 28图像,经过这个之后就是5 * 1 * 1。这免去了全连接层的大量参数,而全连接层的大量参数有可能减慢计算速度和造成过拟合。不过AdaptiveAvgPool2d有可能导致收敛速度减慢。
NiN的设计事实上很多部分来自AlexNet。结构如下: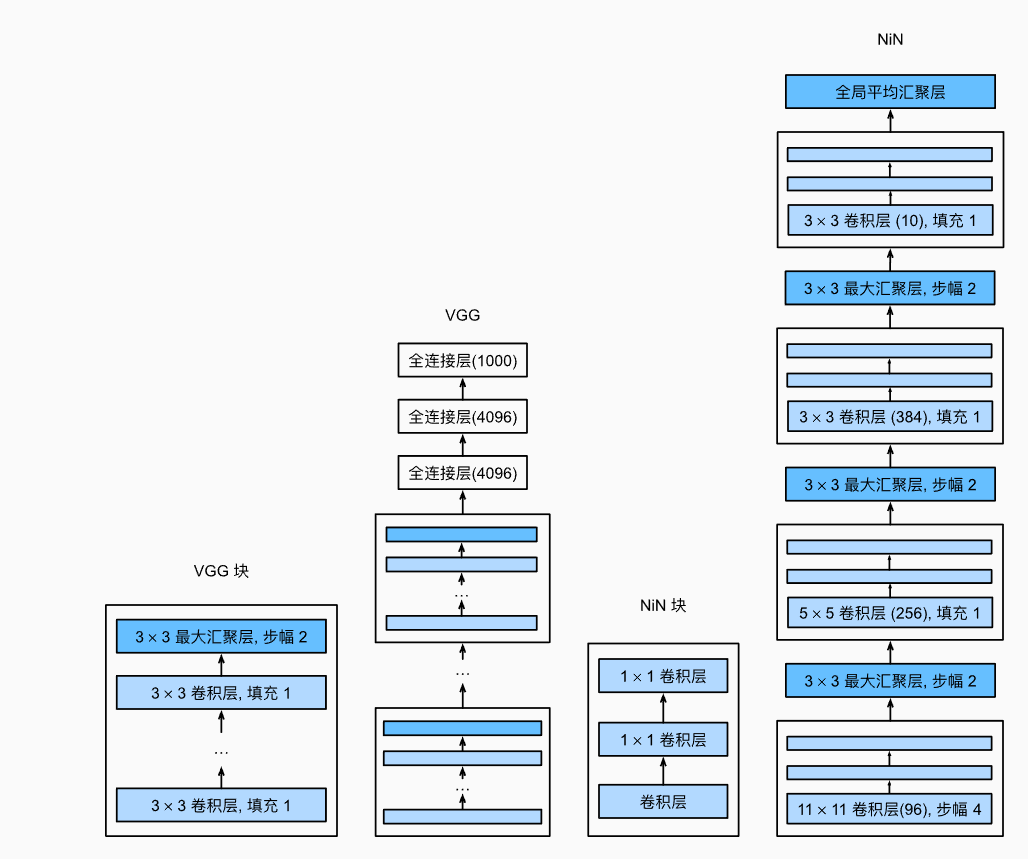
很遗憾,在小批量的数据上NiN的收敛速度的确很慢,我在取5000张fashion_mnist数据集的训练中收敛极慢,没有复现成功。其网络架构为:
1 | def ninBlock(inChannel, outChannel, kernel_size, padding, stride): |
GoogleNet
GoogleNet论文指出,有时候使用不同大小的卷积核是有利的。GoogleNet应用对一层信息的多次conv,类似不同大小的滤波器可以提取到不同的信息,最后拼起来作为输出。一个模块如下: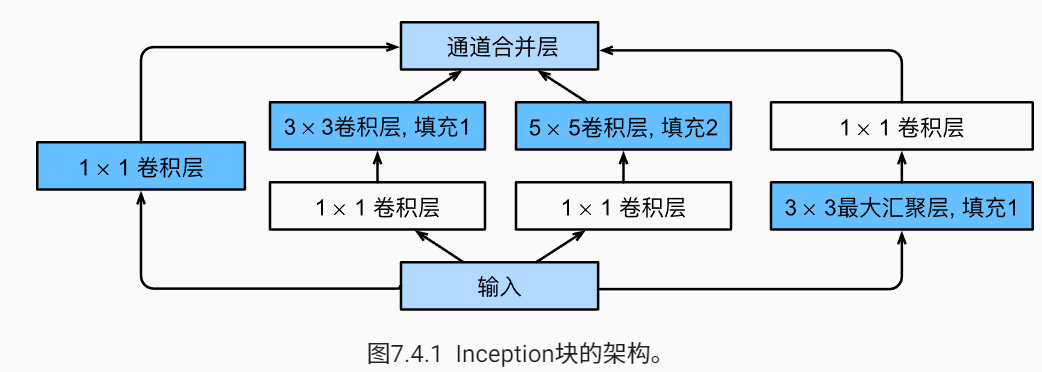
而整个网络架构如下: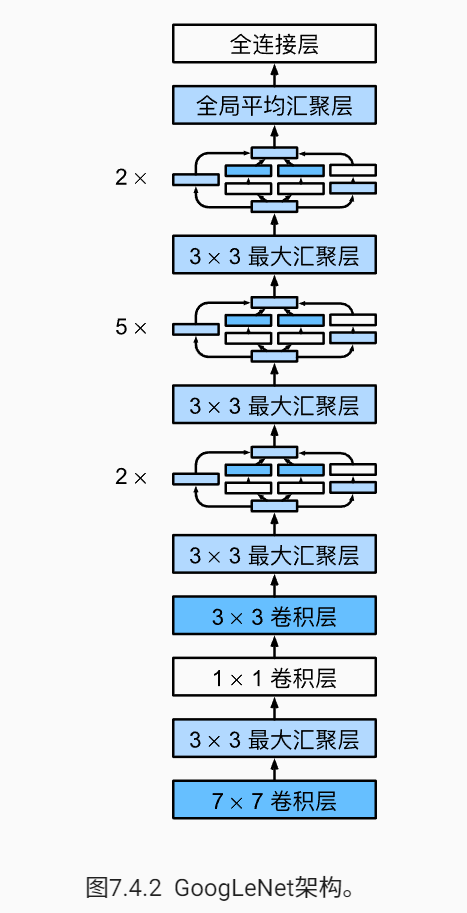
这里给出简化过的GoogleNet实现。
1 | class Inception(nn.Module): |
ResNet
ResNet直觉上把要拟合的f(x)变换成f(x)-x,这在一定程度上更好实现,如下: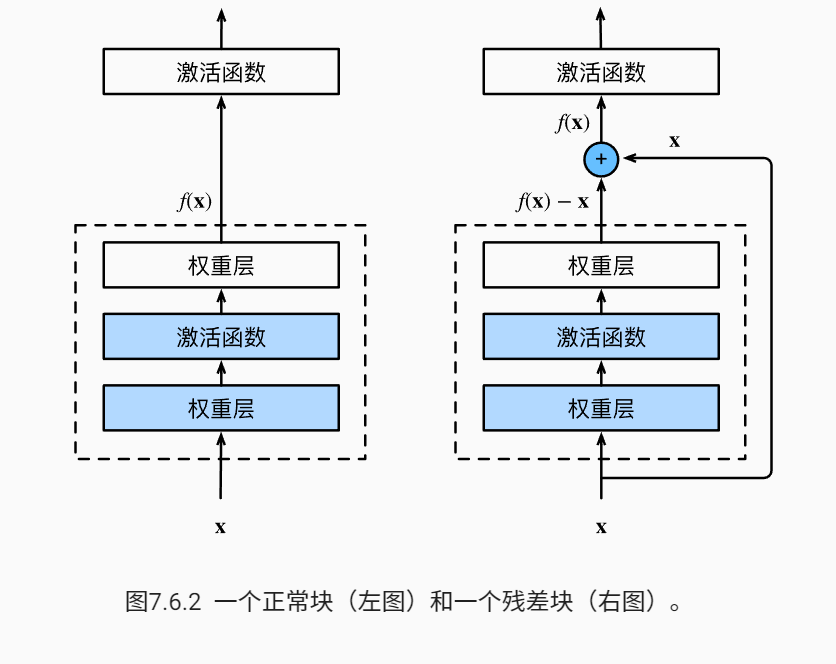
因为ResNet块中,有的时候想要在conv指定大小的变化,如果直接加到后面去维度是不匹配的。所以引入另一种块,即使用1*1conv变化维度,使其可加。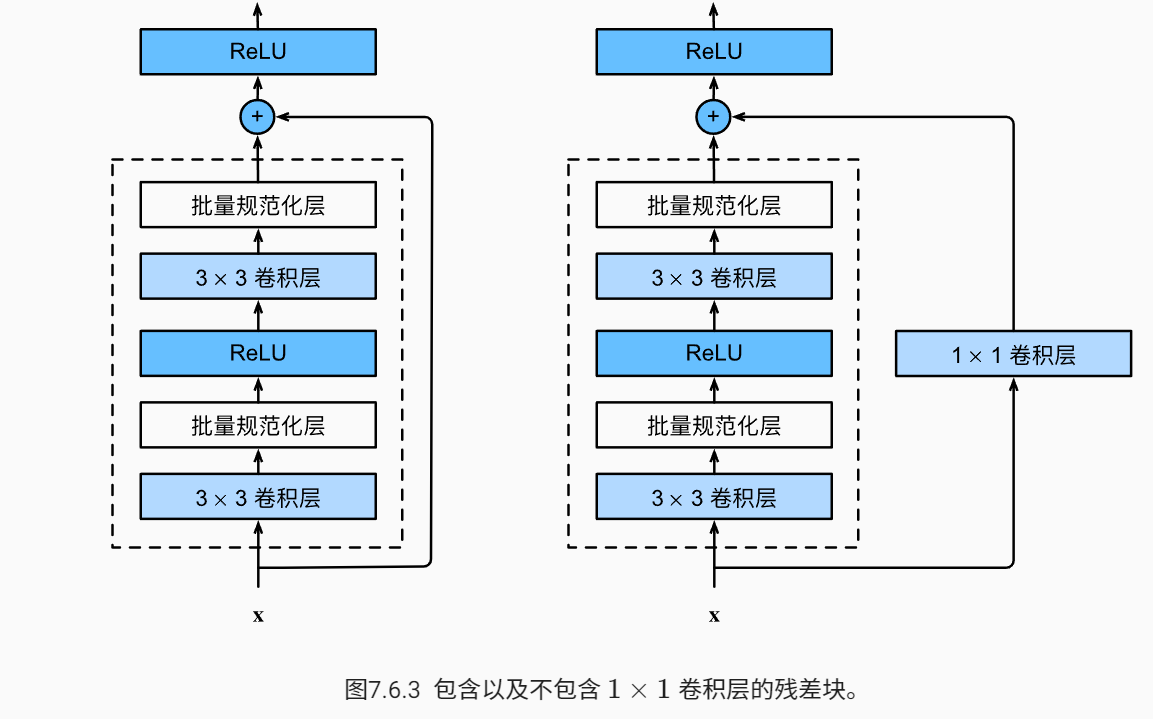
那么ResNet的总架构由这些块构成,如下: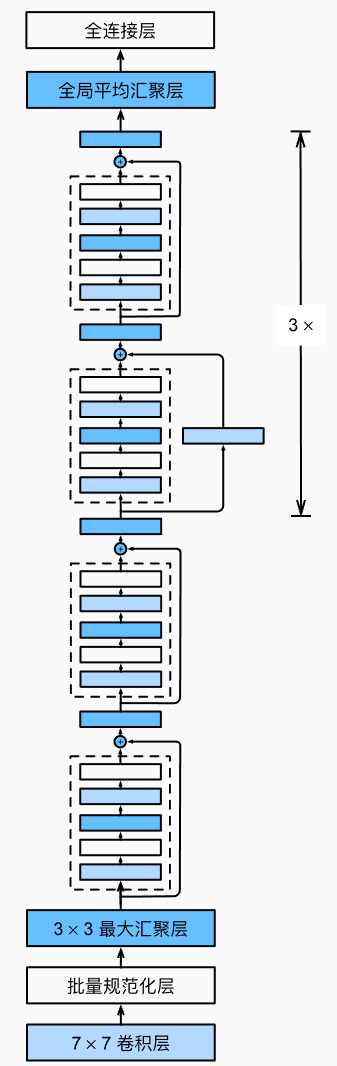
实现代码如下:
1 | class Residual(nn.Module): # 定义块中要用到的元素 |
DenseNet
DenseNet在ResNet的基础上对每个块之间都进行了连接。具体表现为,当经过一个DenseNet块之后,处理的输出会append到输入矩阵中,进行下一个处理。但这样会带来问题,就是输出越来越大。为此,使用过渡层,即1*1conv后接一个AvgPool,对输出规模减小。
此外,DenseNet使用了更新的块顺序。即BN-activate-conv。代码如下:
1 | def conv_block(input_channels, num_channels): # 定义基础conv,下面的DenseBlock要用到 |
YOLO复现
YOLO是物体检测的高效实现。给定一张图片,我们可以通过YOLO检测出多个目标并给出目标大小。其具体实现脉络如下:
输入图片->图片通过CNN得到一个特征张量->从张量中得到特别多的目标框->去掉其中概率太小的框->选定最大概率的框并去掉与其交并比太大的框->得到结果
寄了,没做出来,本贴终结。