
统计学习方法 一到四章笔记
第一章 概论
习题参见[https://datawhalechina.github.io/statistical-learning-method-solutions-manual]
1.2 分类
基本的分类
分成监督学习、无监督学习、强化学习、半监督学习和主动学习。其具体定义略。
按模型分类
概率模型和非概率模型
- 在监督学习中:
- 概率模型是生成模型,非概率模型是判断模型
- 概率模型的分布是P(y|x),非概率模型是y=f(x)
- 在无监督学习中:
- 概率模型的分布是P(z|x)或者P(x|z),非概率模型是z=g(x)
做一些常见算法的分类:
非概率模型:感知机、支持向量机、k近邻、adaboost、k-means、潜在语义分析、神经网络
概率模型:决策树、朴素贝叶斯、隐马尔科夫模型、条件随机场、概率潜在语义分析、潜在迪利克雷分配、高斯混合模型
而logistic回归两类都属于。
线性模型和非线性模型
也就是拟合的函数是不是线性的。
比如,线性模型:感知机、线性支持向量机、k近邻、k-means、潜在语义分析
非线性模型:核函数支持向量机、adaboost、神经网络
参数化模型和非参数化模型
参数化模型指模型参数的维度固定,非参数化模型会随着训练数据量扩大而参数维度升高。
参数化模型:感知机、朴素贝叶斯、logistic回归、k-means、高斯混合模型
非参数化模型:决策树、支持向量机、adaboost、k近邻、潜在语义分析、概率潜在语义分析、潜在迪利克雷分配
按算法分类
在线学习:每次接受一个样本,之后学习模型
批量学习:直接把所有样本都学习完
此外,还有贝叶斯学习、核方法的分类。
1.6 泛化能力
在学到了模型
这里可以找到泛化误差上界,来分析学习方法的泛化能力。课本中有一个简单的二项分布例题。
1.8 监督学习应用
二分类中的指标有准确率和召回率。即总共有四种分类情况,TP, TN, FP, FN,分别指正类预测为正类,正类预测为负类,负类预测为正类,负类预测为负类的数目。
准确率P = TP / (TP + FP)
召回率R = TP / (TP + FN)
f1 score满足:2 / f1 = 1 / P + 1 / R,也就是P和R的调和平均,翻转得
第二章 感知机
2.1 感知机模型
感知机是SVM和nn的基础。
感知机:给定输入空间
感知机的假设空间是特征空间里面的所有线性分类模型,也就是
感知机的直观解释: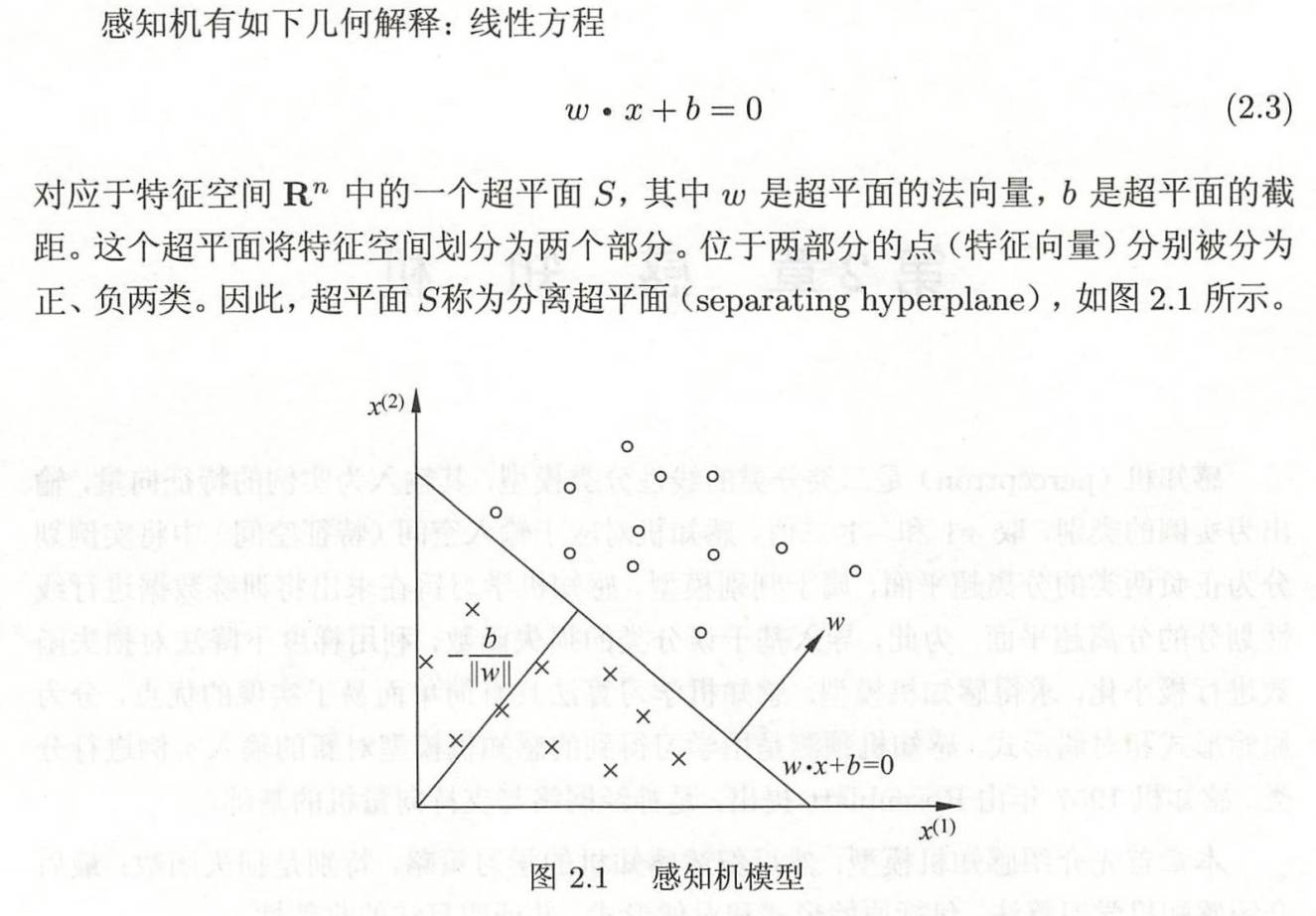
2.2 感知机学习策略
在上面定义了问题之后,对于所有的数据
如果存在某个超平面
但是感知机的学习是对
对于分类错误的样本,有:
有了这个,而且y只有1和-1的取值,那么直线距离的式子可以脱去绝对值号,也就是这条式子是为了脱去绝对值号而提出来的。
对于所有的误分类点集合
因此在这里,为了更好地定义损失函数,感知机学习的损失函数就是这里把
在这里,误分类点离超平面越近,loss越小。
但是为什么要这么定义,把
2.3 感知机学习算法
在知道了感知机的目的之后,自然需要知道怎么降loss。
也就是求得这个问题的解:
方法是用随机梯度下降(SGD):
这个算法的例子见课本40页。注意到,最后收敛的结果会随着
有一个漂亮的理论(novikoff定理)给出了在训练数据集上误分类次数的上界(课本42页),也就是在线性可分的时候,感知机总能收敛。
感知机学习算法有其对偶形式,可以加快运算。方法是把
其中
有了这个,可以定义对偶形式:
注意这里(2)(3)的i是同一个i,也就是选了第几个样本就是要对
可以看出,可以先计算出
第三章 k近邻法
3.1 k近邻算法
这里只讨论用来分类的k近邻算法。

3.2 k近邻模型
这里的k近邻模型使用的距离可以是
这里p=2时是欧氏距离,而p=∞的时候,有
至于提出这样的距离,自然是因为在使用不同的p值下,“最近”的这个结果是不同的,p是一个超参数。
k是一个非常关键的超参数。
- k值比较小的时候,学习的域就很小,近似误差(approximation error)变小,然而估计误差(estimation error)会变大,因为减少了看的点的个数,会对周围的点变得敏感,带来过拟合风险。k值变小使整体模型复杂;
- k值比较大的时候,减少了估计误差,增大了近似误差,这个时候和输入很远的样本也考虑进来了,k值增大使模型简单。
k近邻还有定义一个误分类的概率,在0-1损失下,多数表决策略的误分类率:(这有点反直觉)
3.3 k近邻法的实现:kd树
然而逐个点去算k近邻是很不好的,这叫做线性扫描。
可以采用特殊的数据结构,减少计算距离的次数,kd树是一种方法。
kd树是对k维空间中的点存储来快速检索的数据结构,是一种二叉树。
构造kd树中,kd树是平衡的时候搜索效率未必最优,但是是一个不错的策略。方法为:

这个区域划分的kd树中每一个结点的位置上都有数据。
课本的例子:
给定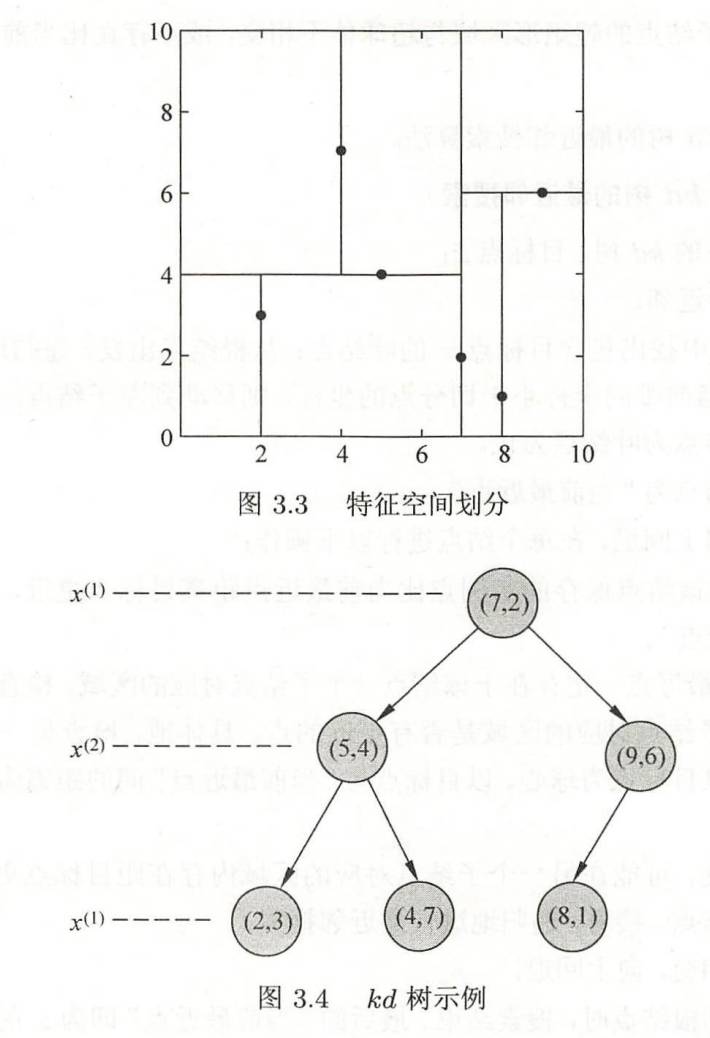
注意,最后一层的叶节点是一整片区域,其实再在上面画线没有什么用处。
构建好kd树之后,可以用kd树做k近邻搜索。

搜索方法的例题如下:

第四章 朴素贝叶斯法
4.1 朴素贝叶斯法的学习与分类
4.1节主要是介绍为什么朴素贝叶斯是这么算的,具体算法见4.2节。朴素贝叶斯的直观性肯定是不如第二第三章的,所以这里花了一些篇幅来说明“为什么”这件事情为了让你看不懂。
朴素贝叶斯法也是一个用来分类的方法。其余设置都和普通的分类方法一样,然后强调X,Y的联合分布
问题是,怎么学到
以及条件概率分布:
就可以有
朴素贝叶斯里面做了一个比较强的假设,就是各个特征之间相互独立,叫做条件独立性的假设(这个假设让朴素贝叶斯法更简单,但是有时会牺牲准确度),也就是:
在有了这些东西之后,怎么用朴素贝叶斯分类器做分类?
依贝叶斯定理(其实用全概率公式推一下也知道):
那么对上式取argmax就是分类的预测结果,即:
下面是正确性的证明,不看证明的话可以跳过到4.2节。
为什么这里这么算,把实例分配到后验概率最大的类里就是对的?
这里可以证明这样等价于期望风险最小化。期望风险越小,可以认为模型越好。然而课本这里的证明过于简略,难以读懂,下面证明会给出一些解释:
考虑损失函数为0-1损失函数,也就是:
这个时候的期望风险函数为
由于
这就是我们在朴素贝叶斯里面做的事情。
4.2 朴素贝叶斯法的参数估计
极大似然估计
这里的参数估计其实只有指导意义,实际上就直接把频率当概率就可以了。
课本给出了
也就是直接的频率,也就是
设x的第j个特征的可能取值为
还有条件概率的极大似然估计为:
通俗地讲,这就是
那么朴素贝叶斯算法就是:
例题:


贝叶斯估计
贝叶斯估计是为了解决概率值=0时候出现的问题。修改一下
这个加上λ的技巧,取=0就是极大似然估计,取=1叫做拉普拉斯平滑,一般使用拉普拉斯平滑。
同样,先验概率也变成了: