
神经网络基础 & softmax多分类
一些基础约定
我们称输入层在神经网络中是第零层。
然后剩下的层数才是神经网络的深度。参数的上标,在神经网络中若为方括号,如[1],说明这来自神经网络的第一层,或与第一层相关。这主要是与圆括号表示样本序号区分的。参数的下标就是这一层的第几个参数。神经网络确定维度是更重要的。举个例子,第一层中有四个神经元,输入层有三个输入(一个样本的三个维度)。我们应该怎么去得到第一层的输出?按照Logistic回归的知识,w被初始化为(n_x, 1)的一个列向量,b是一个数。在这里,我们将w堆叠,得到(n_x,4)的一个矩阵,那么W.T.shape就是(4,n_x)。(按方括号的记号约定,这里的W应当写作W[1]。)然后为了得到最终的结果z[1],我们还需要b[1]。那么很显然,W.T.dot(X).shape就是(4,1),这就是b的shape。
综上,我们得到Z[1] = W[1].T.dot(X) + B[1],其中W[1]和B[1]的维度就是上面所说的。为了统一起见,把这里的X写成a[0]。后面层数里面,同样我们可以得到Z[2] = W[2].T.dot(a[1]) + B[2]。
建议所有矩阵的写法都像Andrew Ng在slides里面的写法,即x(i)写在中间,其元素表示成竖线,这样十分清晰。
在这里的多神经元初始化,不能全都初始化为0,一般是取随机数。而且取完随机数之后一般乘以0.01让它靠近tanh或者sigmoid梯度较大的位置。(在Andrew后面提及的别人的成果里面,一种relu激活函数下更快的初始化是w[l]在随机后乘以np.sqrt(2/n[l-1]),这通常表现得更好)注意,前面说的是只对W说的,B的初始化仍为全0.
各个要用到的导数结果以及维数结果
对单样本的时候,我们的导数都是对L的。结果为:
1 | dz[2] = a[2] - y |
但是问题出在多样本的时候的分析。我们知道,多样本的时候,有J = (Σ(L)) / m。但是Andrew Ng给出的结果却是如下:
1 | dZ[2] = A[2] - Y |
我到现在都不知道为什么dW和dB需要除以m,而dZ的结果不除以m。那只能把这个结果记住了。
此外分析得知,dW[2]和dW[1],以及dB[2]和dB[1]的结果结构相似,都是对应上标-1(X应看作A[0])。
所以我们在隐藏层数更多的时候,归纳得出:
1 | 在第l层的参数: |
另外,考虑维数,其实有更为好用的一个结论:**W[l]的维数总是(n[l], n[l-1])。
其中l从输入层,即第零层开始算起。n[l]就是所在层的神经元个数,特别的,n[0]就是单一样本的特征维数。
同理,Z[l]的维数(当然,A[l]的维数也等于这个)是(n[l], m)。 m是样本个数。
而且有了broadcast的存在,B[l]的维数就可以是(n[l], 1)**。
正确的调参姿势
当bias比较大的时候,即在train data上表现不佳的时候,可以采取以下方法:
1. 采用更大、更深的网络
2. 训练的时间更长
3. 更换神经网络架构
当varience比较大的时候,即在validation data上表现不佳的时候,可以采取以下方法:
1. 使用更多数据
2. 正则化
3. 更换神经网络架构
一般来说,这么多超参数里面,最为重要的是α。次之是momentum的β1(一般取0.9),隐藏层的神经元数目,batch的size;更次之是隐藏层的层数和学习率衰减。Andrew一般不会去调ADAM的β1(一般取0.9),β2(0.999),ε(1e-8)。
而且在超参数的测试中,Andrew建议使用随机超参数,以此获得超参数比较好的一个范围(而不用均匀超参数取值去测试,至于均匀超参数怎么取值可以翻课程视频)。而且,当在当前这个大范围中找到一个小范围更好的取值,那么就在小范围内取更多的值来测试,从取值从稀疏到稠密。
而且,随机取值建议取对数。比如,lr的取值如果从0.001到0.01均匀随机的话,较小的部分并没有被很好的探索,而其中lr在比较小的时候的扰动会对结果有比较大的影响。所以取对数之后,lr取值在0.01到0.1的概率和0.001到0.01的概率一样大,这可能会更好。就像β在0.9到0.999中,越靠近0.999就越敏感(因为1 / 1 - β^t),所以应该取对数让他在0.9到0.99和0.99到0.999之间概率近似相等,就更好了。
正则化
在神经网络的正则化中,我们对原先的J做出了修改:
1 | J = Σ(cross-entropy) / m => |
在这一修改下,dW[l]也变为
1 | dW[l] = dZ[l].dot(A[l-1].T) / m + λ * W[l] / m |
不过dB倒是不会改变。
此处λ也是一个超参数,而且在python中为了避免和关键字重名,写作lambd.
上述的方法也被称为L2正则化方法。事实上,我们还有一种正则化方法,称为dropout。dropout中最常用的是inverted dropout,这是对W[l]的dropout。而且,dropout只在训练集上使用,不在test集上使用,但dropout应在forward和backward里同时使用。具体代码如下:
1 | keep_prob = 0.8 # 举个例子,保留一个神经元的概率为0.8 |
不过dropout通常没有办法得到J这个损失函数。
在正向dropout之后还要拿到d[l]这个矩阵,这需要同样被backward使用,即
1 | dA[l] = d[l] * dA[l] |
还有一些其他的正则化方法。比如,在图像输入中,如果不能获得更多的数据,我们可以水平翻转图片、裁剪图片或者变形的方法。
或者,我们可以采取early stopping的方法。我们将在trainning set和validation set的error画出,这通常为:trainning set中的J是单调递减的,然后validation set的J先减再增。我们在其中的最低点处停止学习。
不过early stopping和l2正则看起来走向了两个极端。early stopping只跑了一组hyperparameter,然后在当前这一组数据中挑了一个最好的点。但这可能会带来问题:我们放弃了更好的trainning set精度来换取方差精度。而l2正则要跑很多组λ这个超参数,这是训练时间的消耗。
归一化
当样本的多个特征之间相差比较大的时候,如x1从1取值到1000而x2从1取值到3,在这种情况下归一化非常重要,这加快了训练过程。这应当在训练之前就去判断一下是否应当实现归一化。不过尽管特征之间的range相差不大,实行归一化也是可行的。归一化其实和概率论中的定义一致。即对多个样本求出其方差和均值,将所有数据都进行变换:Z = (Z - μ) / σ,然后再实行A = g(Z)。但应该注意,这一变换不仅在trainning set上实行,validation set也应该实行。
当然,上面所说的归一化是对Logistic的。那么我们可不可以把这一技术用到dnn里呢?当然是可以的。
Andrew建议使用Z[l]的归一化结果,记作Z_tilde[l]。其中,记一个batch得到所有的Z的均值为μ,方差为σ ** 2,Z_norm = (Z - μ) / σ。
不过我们不总是想让归一化的变量服从标准正态分布,引入新参数γ[l]和β[l] (这里的β[l]并不是超参数)。
从而Z_tilde[l] = γ[l] * Z_norm[l] + β[l] (第一个乘号是element-wise的),这样我们得到的Z_tilde可以按我们想要的方式服从其他的分布。
不过,既然引入了两个新参数,那么这两个新参数也应该通过梯度下降进行更新。
综上,我们得到了归一化背景下的学习流程:
1 | Z[l] = W[l].dot(A[l - 1]) + b[l] # 这里可以不用加b[l],原因是我们后面减去均值的时候就算加了b[l]也会被减掉 |
应时刻记住,BN是对一层运算后的所有样本之间计算实现的,这总在conv或fc后,且在activate之前实现的。具体可以看https://zh-v2.d2l.ai/chapter_convolutional-modern/batch-norm.html#
batch-normalization(简称bn)的作用体现于,计算出来的Z[l]总是受标准正态分布或者我们给定的γ和β控制的,这使得前面的神经元计算出来的结果偏移不大,后面的神经元学习更有效,从而减轻了前面神经元计算的结果对后面神经元的影响。
此外,bn还有轻微的正则化效果。举个例子,dropout有正则化效果是因为dropout会随机disable一些神经元,这会带来噪声。噪声就会使得这个模型更加robust。而bn中,由于batch是部分样本,batch求出来的均值和方差也会有轻微噪声,毕竟这不是整体。受这些噪声影响,bn也会带来轻微的正则化效果。不过不必寄希望于这一点正则化效果,这更多的带来是训练效率的提升而非正则化效果。
梯度检验
梯度检验在debug中使用,被用于检查我们推导出来的梯度公式到底对不对。
这里要用的梯度不用数学分析上的梯度,那个精度不够。我们使用dθ = (f(θ + ε) - f(θ - ε)) / 2ε。在这里,为了与我们公式算出来的dθ区分,我们用前面的数值方法求出来的记作dθ_approx.
梯度检验有几个注意事项:
1. 梯度检验只在debug的时候使用,不要在训练的时候使用。
2. 梯度检验失败的时候应当定位大致错误的范围。
3. 在损失函数含有正则项的时候,梯度检验的式子里面也要带上正则项的导数。
4. 梯度检验不要在dropout是valid的时候使用。
5. 梯度检验比较慢。我们应该只在少数几次iter里面使用。
5. 很少见的:梯度检验有的时候会随着初始化系数不太好用。可以在训练一定时间之后再进行梯度检验。
梯度检验是怎么实现的呢?这里的参数都是矩阵,上面dθ的式子不好实现。因此考虑把我们所有的参数都变成一个向量,然后求出最后的J,计算这个dθ就容易得多。如下图: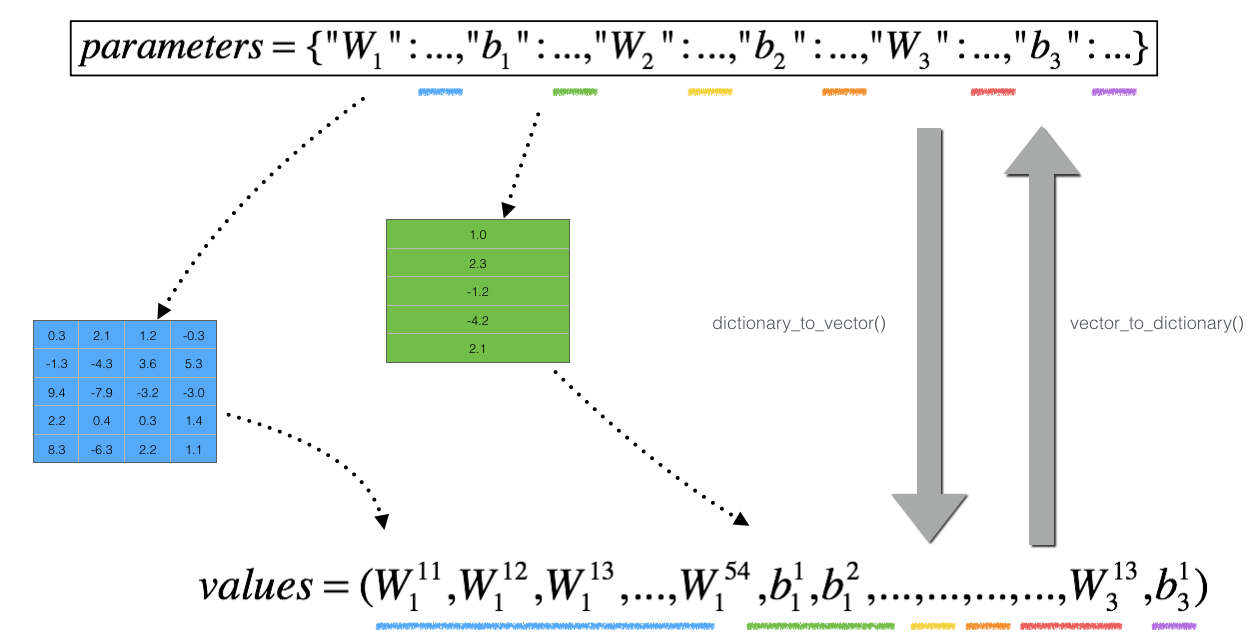
我们将所有参数都拼成一个大向量(其中矩阵按行取出来),这个向量就是J(θ)里面的θ这个大向量,包含了我们所有的参数。这里的dθ和θ的维数也相同,所以我们一次除法只能算出来dθ的一个维度。即
1 | # 这里省略了dictionaryToVector的过程 |
梯度检验在算出来dθ_approx和dθ之后,我们衡量两者的差别(当然,原来的梯度也要转化为vector):
对于difference = (||dθ_approx - dθ||_2) / (||dθ_approx||_2 + ||dθ||_2) # 这里的||·||_2代表欧氏距离,即np.linalg.norm。
如果difference < 1e-7,那么很大概率我们的梯度算对了。反之,我们需要考虑梯度到底对不对。
一些更好的梯度下降优化
在这里,先介绍一个统计学中常用的方法:指数加权平均(exponentially weighted average)。(如果不想深究ADAM的来源只需要应用的话可以不用理会这个方法)
即给定一系列样本点,比如气温在一个月的每一天中的变化。我们用指数加权平均的方法可以对这一系列的点进行拟合,具体如下:
1 | 记vx是曲线上的纵坐标,即第x天对应的气温,估计气温;θx是样本气温。实现过程为: |
但这会有一点点问题。就是前面几天会受v[0]的影响而很小,曲线在前面这块数值偏小。如果完全不关心前面的数值,那么可以直接使用。反之,我们需要对v[day]进行修正:
1 | v[day] = (v[day - 1] * β + (1 - β) * θ[day]) / (1 - β^t) # 在分母添加了修正因子 |
这样,就可以进行更准确的估计。这被称为bias correction。不过这会浪费算力,如果不关心前面的数据,直接用第一条式子就可以了。
有了之前的知识,我们能对小批量样本进行一个不错的神经网络学习。但是当样本数大起来了,上面的过程会变慢。这里有一种新的方法,称mini-batch。
引入新记号,x{i}(其中{i}是上标)代表样本矩阵中第i个批次,即我们将样本矩阵分成很多个子矩阵,每个批次包含若干个样本。对所有的X{i}都做完forward prop和backward prop并更新参数称为 1 epoch(直观上就是把原来的所有样本都跑一遍称为1 epoch).
事实上,我们之前做的梯度下降都是基于整个样本集的。而与之相对的是SGD,每次计算参数和更新参数都只基于一个样本,把所有样本都跑完是一个iteration。这当然也有好处,比较快。两者的效果be like: 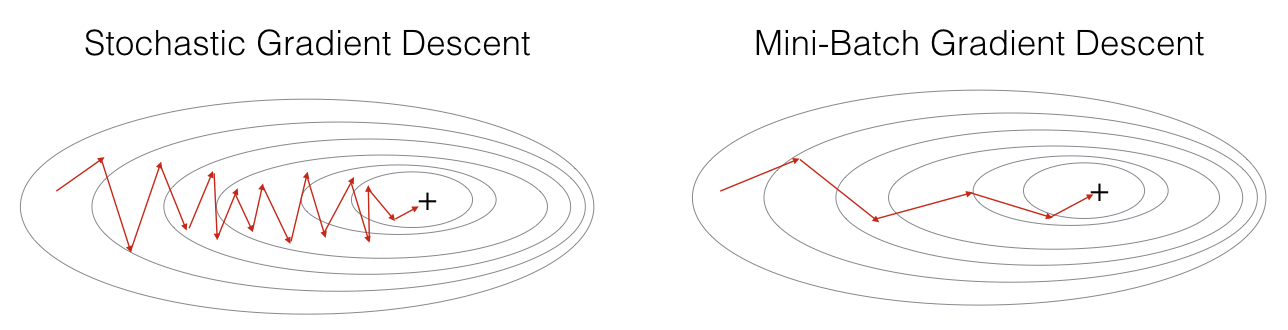
不过,两者折中的方法就是mini-batch。
mini-batch划分之前先要把样本集按样本打乱shuffle。然后再到按mini-batch-size划分这一步。
这里直接介绍ADAM方法,因为这就是Momentum方法和RMS prop方法的结合。
Momentum和RMS prop都是在梯度的影响下对参数进行优化,但并不完全遵照梯度的方向优化的。我们可以相对调大学习率对模型进行训练,这比最基本的梯度下降更快。ADAM方法缝了两个方法,更快了,具体如下:
1 | 在back prop中算出我们要的dW[l]和db[l]之后,并不进行W[l] -= lr * dW[l]这一步,而是用下面的步骤取代: |
学习率衰减。
学习率衰减就是顾名思义,在收敛的过程后边部分,学习的步长如果还是很大的话,会在最小点附近徘徊,有可能徘徊比较远。如果让学习率随着iter减小,就能减轻这样的徘徊,让loss更靠近最小点。不过学习率衰减,根据Andrew的经验,他不会在第一时间考虑学习率衰减这个问题。这只作为备选项考虑。
softmax多分类
截止至目前,我们的任务还只停留在Logistic,二分类上。我们可以通过修改最后一个激活函数和Z[L]的shape(L是最后一层)使得分类的类别更多。具体为:
1. 我们将最后一层的神经元数目从1改成要分类的类别数目,比方说分成猫,狗和其他,那么最后一层的Z[L].shape == (3, 1)。
2. 激活函数从sigmoid修改为softmax。其具体为,Z[L] = np.exp(Z[L]); # 把所有算出来的数通过exp转化,我也不知道为什么要这样
Z[L] /= np.sum(Z[L]); # 除以总和,得到的就是分别的概率。
3. 损失函数从交叉熵退化成信息熵。即对单样本,比方说(0.6, 0.3, 0.1)。L = -Σ(y * ln(y_hat)),而这里只有一个y是非0的。那么J = ΣL / m。
4. back prop通常不用关注,框架会帮我们算好如何back prop。不过想推导一下也是可以的。最后一层的dZ[L] = y_hat - y,其中y是按我们上面定义的向量。
评价训练的网络
当我们训练好了网络,我们会得到很多指标来评价我们训练好的网络。Andrew指出,有的指标是满足性的,即超过某个阈值就可以不再理会;如果剩下还有过多的指标,可以设立某种函数关系或者取平均数,把指标的数目降成一个,能更好地选择多个训练出来的网络。
一些工程性问题
事实上,我们可能关心的问题和我们训练的东西不很一致。就像猫图,我们训练集和开发集上的图片清晰,但是用户传的图片有可能很模糊。这种时候,我们需要分清楚方差的差距到底是来源于模型本身没见过同一分布的数据(都是清晰猫图,但是我们的模型没认出来)还是因为数据分布不一致(图片清晰度不一样)带来的差距。
为此,我们可以进行小批量分析。比如,在小批量中确定人类错误率、训练集错误率和开发集错误率。但是为了区分上面说的这个差距问题,我们在开发集中划分一些图片,这些图片和我们的训练集来自同一分布,称为训练-开发集。如果在训练-开发集上的表现和训练集上的表现差不多,说明就是数据分布不一致的问题;如果这两个本身的表现就差距很大,说明是模型自身的方差很大。